|
Summary |
|
| 6th August 2006 |
Cognitive Economic Modelling Notes 5 |
| 21st August 2006 |
Cognitive Economic Modelling Notes 6 |
| 22nd August 2006 |
Cognitive Economic Modelling Notes 7 |
Sunday 6th August 2006: 12.43pm. This will probably be the last entry with detail about my model as I've decided to change tack. The last two weeks or so of reflection have allowed considerable feedback to be received, and if long-time readers of this site can't get their head around what I am saying, then I can't see many other people doing so either. This makes persuading people to help me somewhat hard.
Hence I have decided to switch my efforts into writing v0.1 of my Neo-Capitalism document, which shall eventually get published in my Neo-Capitalism website http://www.neocapitalism.org/. This document aims to explain all in one place the thinking required to come at the angle I have been writing about and in theory, should be standalone. I'll test this proposition by submitting it for publication probably to PAECON at some point, and we'll see what happens.
Oh before I begin, yeah the visit to Sweden was good - this time no mosquitoes which makes things far more pleasant. Got to meet almost all the rest of Johanna's relatives and I disrespected Johanna's judgement which was valuable as I hadn't realised I'd been doing that for a while. Also got to see one of my coffee dates I- who is off for her year abroad this academic year which really made my summer as I hadn't expected to see her again until 2007.
Much of the following was originally going to be the entry for the 19th July before the migraines began, however I have stripped it down - in particular removing my prototype model as it's best to not speculate until it's working in front of you. What comes for my Neo-Capitalism document is basically my thinking up to this point, but clarified, contiguous and with loads of references and supporting reading.
If you remember this entry, it talked about the four drives I will be modelling everything upon. However, what I have not yet directly addressed is how the organism actualises those drives.
You can believe I have been thinking about this one single part probably since I realised I could apply Tn thinking to Economics and indeed, to modelling of all autopoetic systems. The major problem with existing modelling techniques is that they assume too much and too little infallibility in the human - use of statistical techniques such as Kalman filtering (widely used method of filtering out noise, filling in blanks and extrapolating trends eg; it's how auto-pilots in aeroplanes can handle varying environments such as cross winds) to model how humans estimate likely futures is both too much and too little. It is too much because humans aren't that good, and it's also too little because it doesn't deal well with truly unpredictable (non-linear) phenomena where you get pattern for short, variable length periods on certain senses in between totally random noise. In other words, you need to be able to switch between ignoring and listening to different sources of information quickly, and it's not always obvious what is information - a Kalman filter, like most linear techniques, depends on valuable data coming into all of its sensors. This suggests, as I have known from the start, a form of dynamic, learning neural network. It is precisely this which scares the bejesus out of most people tackling this problem - as Paul Ormerod said in reply to one of my questions at his lecture last year, he didn't feel he was clever enough to let his model firms learn as the dynamics which emerged were truly horrendous. I have to agree, but I also don't see that we have an alternative.
It is probably easiest to illustrate this process by telling you about something which happens each day here at around 6pm-6.30pm. What happens is that at around that time, bees return to their hive after a day's foraging - I can watch a noticeable increase in the density of them flying past my dining room window which has a spectacular view, upon which my eyes often have rested as I have pondered the intricacies of what I am doing.
Now, at around that time, for some odd reason, bees get confused and tend to hover around the small windows at the top of the main dining room window. They hang there for a while, obviously not sure if they're at their hive. Around half the time they will realise that no, they're not there and turn around and fly off always to the left (where I assume the hive is). The other half the time, they come too far in, then you can watch them make the realisation of their mistake, so they turn 180 degrees back towards the light and of course run straight into the glass.
Obviously bees do not understand glass. They simply can't see it, and will repeatedly run head first into it again and again. Much like us in our own perceptual worlds, most of what happens to us we do not understand though we like to think we do, because otherwise we'd be very stressed out. Now the bee will firstly try to push harder (probably because wind is the usual invisible force stopping it) and will buzz like crazy against the glass, tiring itself out so after about ten seconds it has to take a rest. It will try this pushing harder strategy for about four or five attempts when quite suddenly it will do a 180 and fly into the room, though quite slowly. It has now engaged its "explore for another way out" strategy by disengaging its previous reaction of pushing harder. Unfortunately, its memory isn't very good, because after floating around for a while, it will rediscover the window it was just at and once again run into the glass - though note, rarely at the same place it was last time.
I'm an engineering kind of guy - you've all seen this from what I've written here over the years. I like to test the problem solving abilities of life, so I open one of the large windows rather than shoo it out. I have noticed that the bee doesn't change its strategy - it can probably detect the additional wind currents, but not their source so it can't figure out which parts of the window do and don't have glass. However, by iterating the same strategies as before, it does eventually find the open part of the window through enough repetition that it strikes lucky. This is called in the trade a Monte Carlo method, which is basically a brute force randomised but targeted trial & error problem solving.
Note however the very simple rule-of-thumb: If at first you don't succeed, try harder. If that doesn't work after a few attempts, do a 180 for a while and start again.
That simple process underpins a HUGE quantity of animal, and indeed plant, behaviour. Think of the number of Prime Ministers and CEO's who have done U-turns even less ceremoniously than the bee! In a world where we have inaccurate knowledge of our surroundings and insufficient experience for any new task we perform, we basically are constantly going down paths we'll have to U-turn back along to take a different path. A lot of young people in particular very much fear making mistakes, and so spend much of their early 20's paralysed, preferring to not choose any path and unfortunately not realising that that is the worst path of all. The mark of a seasoned computer programmer when working on cutting edge code is that they deliberately design for making design mistakes, so that the change ripples from subsequent alterations are contained. This implies highly complex fractal structure manipulation, which becomes both ever more complex AND ever more simple as computers improve.
We tend in Western society to underestimate the role of rule-of-thumbs in our functioning. We like to think we are these clever problem solving machines, but as any magician or statistician or marketer knows, or is obvious from visual tricks like the one at the top of this page, people are nowhere near that clever. What happens in reality is that a group of organisms generates an improved model of reality through a subset of its group performing trial & error (interaction). Trial & error is expensive, so a few do it and everyone else takes a copy of their results. The mental model reaches a certain level of accuracy sufficient for most purposes, and becomes habit. What is very important here is that "improved" and "sufficiently accurate" usually means "simpler" and "reduced" much in the way that E = mc2 is vastly simpler than all the theory which underpins it. Necessary in all theory/rule-of-thumb is that it is wrong in certain circumstances, or rather that it is only good for a subset of conditions.
{kind=link}
Most people, especially in today's specialised society, rarely test these rule-of-thumbs for themselves and instead rely on what society tells them other people's results are. Note the disjunct - if society is not listening to those who do test the rule-of-thumb, society will go on believing erroneously. This is directly equivalent to society's value system judging who is important to listen to. Note this is precisely equal to the process of cognition. You would be correct in viewing money as a representation of society's value system, of how it sees itself and the world around it (eg; why gold seems always to be treated specially among 'precious' metals). One can also see that by injecting large amounts of free low-entropy energy (fossil fuels), we have seriously upset the 'invisible hand' which normally balances our economy with natural entropy flows and keeps our worldview synchronised with reality.
Ok, back to the model! As I have mentioned previously, it will be of groups of interlinked groups - a web of groups - hence it being called "The Web Of Life" in honour of the book of the same name. In each attribute, much like last entry's discussion about energy & entropy, the quality/quantity methodology is maintained. As has been known for many years, neural networks are equivalent to a set of logical rules-of-thumb. Unlike specifying the logic manually as one does in a computer program, they are "black boxes" which apply those rules to inputs and you can dynamically adjust the rules over time by changing the relations between the groups - or even better, get each group to decide on its own what it will and won't perceive (learning).
Something very important which I have not previously addressed needs to be dealt with before I begin. As I've said many a time before, entropy measures quality of energy, with low entropy being capable of doing lots of work and high entropy very little. However, why is this? Let us start, much as Einstein did when creating relativity, with a ray of light. Light is photons with a high frequency, and therefore a low entropy. Photons oscillate in and out of our macroworld until they get ensnared by something with mass ie; matter. Photons exist below the quantum world in that any quantum relation (subatomic particle ie; organisation or structure) in the quantum world is no more than a particular arrangement of energy. Everything is energy, so it by necessity must predate structure.
Structure is also a source of low entropy, but you must bear in mind that this is not the same kind of entropy. To maintain a new source of low entropy ie; structure, you must continuously generate entropy ie; structure is an emergent property of the generation of entropy. What is basically happening is that you are converting energy-type entropy into information-type entropy. In reality, both types are quite distinct and should have two totally different names, hence me calling the information-type entropy inforenergy back a few entries ago. This gets even more confusing, because inforenergy is also energy, but it's organised energy.
This directly correlates with the difference between mathematics and computer software which I outlined here many years ago. Computer software is organised maths, it is maths with context. This double use of the word 'entropy' happened almost by accident in the form of a faecetious comment made by inventor of computers John von Neumann at the Macy Conferences to communications theorist Claude Shannon that he should start using the term entropy when discussing information because "no one knows what entropy really is, so in a debate you will always have the advantage". This unfortunately led Shannon to grandfather his theory of information, which became central to signalling theory, using the same term 'entropy' in the same but different way. This has probably led to more wasting of time through misunderstanding than we will ever know. Indeed, Richard Feynman dealt with each deliberately very separately in his books, deliberately assigning no unit to information entropy. An excellent webpage attacking both Darwinism and Creationism by explaining this is here.
So we can now see that, put simply, the frequency of a continual flow of photons is "used up" in the generation of inforenergy, which is structure. Thus we get the macro world we see around us which is nothing more than structured energy. Matter captures high frequency photons and converts them into maintaining internal structure by exciting their atoms ie; they get hot. Hence why nothing in the Universe is actually at absolute zero - it's always slightly above, because if it weren't then its matter would decohere. Life, a subset of matter and an emergent property of matter, captures high frequency photons into glucose, and use that glucose to maintain more advanced forms of structure ie; living things which also decohere when the energy flow stops. Humans, a subset of life and an emergent property of life, capture glucose and use it to maintain even more advanced forms of structure ie; mind. Mind, a subset of and emergent property of more complex life, captures glucose and inforenergy and use it to maintain even more advanced structures again eg; love, language etc - but note that if you deprive a human totally of sensory input, their mind decoheres quickly and permanently even if their body remains healthy. Generally speaking, no increase in quantity of photons processed is required to keep improving structure - simply the arrow of time. This increasing of structure is no less than technological improvement itself, which is equal to genetic evolution over time for most life forms. To our knowledge, there is no limit to growth in this area.
Our model must therefore follow this description. It must copy the fundamental behaviour of the Universe - it must be consistent not only with human behaviour, but also bacterial, quantum and anything else you can think of where group dynamics apply. It must be reality boiled down to its essence - how structure is advanced at its most fundamental level.
Therefore, the only fixed rules the model must apply is the conversion of high frequency photons into structure which is equivalent to doing work. I have spoken in previous entries about the magnifying effect of continual human interaction - this is really about creating structures which enhance the operation of other structures (technology, but also love, family, positivity, good ideas, language, making love etc) but equally, it is about structures competing with one another and superior structures replacing inferior ones. Also of course, there are breakdowns of structure - disease, poison, insecticides, war - these usually are contained as forms of creative destruction and therefore are good, but sometimes they are wholescale attacks on life just for the sake of it when they run out of control. A good example is cancer, where inferior structures supplant superior ones much like we dump artificial fertiliser on ground where natural fertiliser would serve better. Disease causing viruses would be very similar - 99.99% of viruses are vital information transports between bacteria, but occasionally you get destructive structures which cause a great deal of damage. Much like with the seasoned computer programmer example above, the whole point of fractal structures is to limit the ripples of damage caused by such malign exogenous actors. You can similarly view youth as well maintained and vital structures with age causing degradation and thus sickness.
If your head is hurting at this stage, then don't worry - I will be hand holding readers through this thought process in my paper. Be happy!
Monday 21st August 2006: 4.06pm. Well, the summer ends on Thursday! Boy has this summer flown, and I have even less tangible to show for it than usual! Nevertheless, I have put together a 14,000 word document called 'Neo-Capitalism v0.1' which I will publish on this website once Johanna has made her intelligibility improvements. It's basically a summary of theories of Systems Thinking which slowly takes you towards a proposed cognitive (rather than the traditional mechanistic) model of Economic behaviour.
While I am now much better versed with the details of the theories, there still remains the problem of a plausible model. Obviously, we need multiple cellular automata each with different relations reflecting what it models. So, as the simplest possible example, you would have one cellular automata modelling the photosynthetic biosphere and another for humans, with the human automata somehow manipulating the photosynthesis for either its own gain (capitalism) or for the gain of the biosphere (neo-capitalism). To my knowledge, no one has yet successfully achieved this sort of combination - I couldn't find any examples during extensive research.
The problem is one of conceptualisation. I can visualise an automata with each node containing a nitrogen, water and plant content whereby the higher the plant content, the more sunlight that node can acquire and the quicker the plant content increases. However, growth of plant content requires sufficient free nitrogen (say >2% of nitrogen already bound up in plant content) and a higher regular consumption of water and indeed sunlight required for maintenance. A percentage of water gets taken from all nodes containing water by an amount proportional to received sunlight and added to each node with a tiny amount of nitrogen in the automata in a fixed randomised way (ie; the pattern is fixed from the start but initially generated randomly - note there is still randomness in quantities added as received sunlight varies) but where a node gets more water, it gets less total sunlight (because clouds reflect). Each iteration, if a node has too much water (the more free nitrogen it has, the more water it can hold) it pushes its excess into its neighbours according to whoever has the least, taking with it a corresponding percentage of the free nitrogen content of that node. Any water reaching an edge node gets returned to 'the sea' which is a virtual set of nodes representing 70% of the total, and of course any nitrogen in that water is lost.
The dynamics are interesting. One should observe that nitrogen quickly gets locked up by plant content, but furthermore the automata should structure itself to best absorb excessive rainfall in order to maintain at least 2% free nitrogen with none getting washed away. If a node rapidly increases its plant content, it can use up its free nitrogen store and thus decrease its water capacity and therefore become much more reliant on external sources of water (and nitrogen). Equally, if rainfall is high one year, it can cause 'flooding' and thus loss of free nitrogen (and thus cause a corresponding loss of plant content until free nitrogen >= 2% of bound nitrogen), though note that it will tend to get 'mopped up' by surrounding plant content where that is sufficiently dense. I also rather like the way we can simulate global dimming by altering the albedo of rainfall.
Combined with this is another automata reflecting humans. This much more resembles a neural network, and basically its aim is to manipulate the biosphere automata in order to acquire plant content. The questions start arising when considering how to get that neural network to do things - for example, how to transfer water from a plentiful source to a less plentiful one. Doing such things can be made more efficient through tools, so now we must allow the neural network to invent new tools - when do we decide when order of involvement changes (eg; you could have a row of men with buckets moving water expending their effort directly, but technology might allow a waterwheel which pumps for you - now all you need is a small group of men to maintain the waterwheel). Do you encode a list of technological advances, or do you let the automata create its own? Obviously, one prefers the latter, but how can you mesh such an abstract thing with such a real biosphere?
If you change tack, and make the biosphere also purely cognitive, you solve this problem but create a new one of being able to interpret the results at all. As one can see from Process Physics, a purely cognitive model speaks its own internal language to itself which we can never understand due to lacking a common meta-language between us and the model. As one can see, we have a problem!
It may just be best if I pushed on with the biosphere model, included a description of same in the document, and published on the basis that it'll kick off a ball rolling. That'll have to be done in my few days in St. Andrews before term starts which is good as that means something interesting to do when I'm not planning the umpteen things I need to for the start of term! My timetable for the next few weeks is pretty good - I spent Thursday till Tuesday in London, then I'm in St. Andrews for a week and a half until I pop off to Madrid for a few days. Johanna will be with me when in London and Madrid, but the early September part I'll be in St. Andrews alone. Perfect for constructing a biosphere automata!
Anyway, I must get going as it's poker tonight, so be happy!
Tuesday 22nd August 2006: 11.44am. Last night I went poking around the internet looking for nitrogen fixing rates in order to get some idea if the model I proposed yesterday was reasonable. One has to include a nitrogen cycle as a simplified proxy for making sure waste goes where it's supposed to go so from an economic point of view, it's probably even more important than the carbon cycle.
What I thought was interesting was how hard it is to get some hard estimates for nitrogen fixation. No one actually seems to know, but everyone is agreed that human nitrogen fixation is definitely more than all performed by nature so we have effectively more than doubled nitrogen fixation. I think the lack of focus on nitrogen is because it's viewed as "not a problem" unlike carbon which is, but only because of global warming. Indeed, ten years ago you would have been hard pushed to get better than guesstimates for the carbon cycle as well! Of course, excessive nitrogen fixation probably causes more environmental damage than all of man's other polluting combined so it really is a problem.
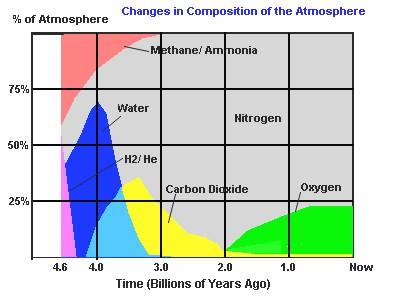 If
humans did not get involved, the first limiting factor for plant growth in
most parts of the world is free water. The second limiting factor is
availability of nitrogen. In temperate climates such as here in Ireland,
there is plenty of free water during the entire year, but the nitrogen
supply is somewhat limited. If you look at the graph on the right, you can
see that the proportion of nitrogen in the air has been steadily increasing
during the planet's history to its majority position today at around 78%.
Most people think that large atmospheric amounts of highly-reactive oxygen
is the most typical feature of living planets, however note that both Mars
and Venus have 3% of their atmospheres being nitrogen so a high nitrogen
concentration must also be a product of life.
If
humans did not get involved, the first limiting factor for plant growth in
most parts of the world is free water. The second limiting factor is
availability of nitrogen. In temperate climates such as here in Ireland,
there is plenty of free water during the entire year, but the nitrogen
supply is somewhat limited. If you look at the graph on the right, you can
see that the proportion of nitrogen in the air has been steadily increasing
during the planet's history to its majority position today at around 78%.
Most people think that large atmospheric amounts of highly-reactive oxygen
is the most typical feature of living planets, however note that both Mars
and Venus have 3% of their atmospheres being nitrogen so a high nitrogen
concentration must also be a product of life.
Nitrogen can get fixed naturally one of two ways, both of which use nitrogenase enzymes which do not like oxygen at all. The oldest is by bacteria operating in environments without oxygen, which would have been common for much of Earth's history. Obviously due to a great deal of oxygen being around nowadays, this happens now only deep down into soil or much more likely, ocean. The other way is effectively through photosynthesis as it requires very substantial amounts of energy to fix nitrogen - firstly you need a source of hydrogen which one usually takes from water, then you need to combine it with the pretty inert nitrogen gas to get ammonia and in the meantime you need to keep oxygen out. Only very specialised bacteria called diazotrophs can perform this function, and needless to say quite a few plants such as legumes have evolved special symbiotic facilities much like our own intestines to ensure a competitively advantageous nitrogen supply.
So how much nitrogen would get fixed by nature each year? Well, most of it comes from decomposition believe it or not - we eat the plants and when we shit it out, bacteria break it down into ammonia, then other bacteria convert the ammonia to nitrites and still other bacteria convert that to nitrates. This process is far more efficient than fixing it in directly from the air, though it does require plenty of oxygen around otherwise other bacteria will break the ammonia down back into nitrogen gas. This is one of the many reasons why farmer plough fields to aerate them.
So some figures then! The current best guesstimate for non-human nitrogen fixation is 175m tonnes per year. It is reckoned that about 80% of all nitrogen fixation happens on land which of course comprises 30% of the world's surface. Of the land, 20% is covered by snow, 20% is mountains, 20% is desert, 10% doesn't have topsoil which leaves only 30% as being arable land that can support more than minimal life. The total area of land is reckoned to be 148,847,000km2 with ocean being 361,254,000km2, so if one were to assume that 30% of land is responsible for 80% of nitrogen fixation, that means some 44,654,100km2 produces 140m tonnes/yr or rather, 3,135.21 kg/km2/yr. Legumes are known to fix up to 18,000 kg/km2/yr, higher plants up to 10,000 kg/km2/yr and well-aerated soil can achieve up to 1,500 kg/km2/yr without sunlight and up to 5,000 kg/km2/yr with sunlight.
So that's that for the summer! I have to go start packing up my stuff to have it shipped to Scotland so I will be off! Be happy!
Refs:
- http://edis.ifas.ufl.edu/SS180
- http://www.ozh2o.com/h2origin3.html
- http://hypertextbook.com/facts/2001/DanielChen.shtml
| Go to previous entry | Go to next entry | Go back to the archive index | Go back to the latest entries |